I flew into Anchorage after work on Thursday night, landing at a reasonable
time thanks to Alaska being four hours behind Eastern Time. We stayed in
Anchorage on Thursday, did some work from there in the morning and drove up
towards Denali National Park on Friday afternoon.
Before leaving Alaska, we stopped at an outdoor store to buy some bear
deterrent spray. This National Park Service
video
convinced us, though it was unlikely we’d run into a grizzly on the hikes we
had planned. Neither of us fancied running into a male bear given they can tip
the scales at 680 kg and stand 3 m tall.
The drive was nice, we were lucky with the weather for the whole
weekend. We did a couple of short hikes on the way, at Thunderbird
Falls and
Little Coal
Creek
before arriving at our accomodation for Friday and Saturday nights. On Friday I
saw a little of the northern lights;
our host woke us up as they were out. When he woke me up I raced outside in my
pajamas with a jacket on top which was inadequate given the weather! In
hindsight I wish I’d gotten dressed and stayed out there longer. It
was a bit bright where I was standing so didn’t get any good photos.
We were staying about 35 minutes south of the park entrance, so we still had a
short way to go on Saturday morning. We ended up driving further north in
search of coffee, and ended up at the nearest ‘large town’ of Healy (population
around 1,000) where we found somewhere that was still open. We drove through a
few small communities that were all boarded up for the winter which was bizarre
to see. A lot of the businesses shut down completely and the people
working there move south to somewhere warmer for the winter!
The drive along the eastern edge of Denali National Park featured some
breathtaking views of the mountains. Denali Mountain was almost always visible
in the
distance.
It’s the highest mountain peak in North America, with a summit of 6,190 m (for
reference, the highest mountain in Australian peaks at 2,228 m). The upper half
is permanently snowy.
The first hike was the Savage Alpine
Trail,
the first
photo
I took on the hike was of a ‘bears frequent this area’ warning sign so we were
happy to have the spray. It was super windy in some parts, here’s a
video
which tries to capture it (turn your volume down before opening it). After the
hike we drove into the park until reaching the point where the road is closed
for the winter at the Teklanika
River.
On the way out we got our wish of seeing a bear from a safe distance, I’m
glad we got to see one in the wild. It’s a fair distance in this
video,
but it gives you some idea of the size. A group of people assembled to watch
and as you can see about half way through the video it must have got a bit
spooked! We didn’t do loads more on Saturday, but did head out again late at
night to try and see the northern lights.
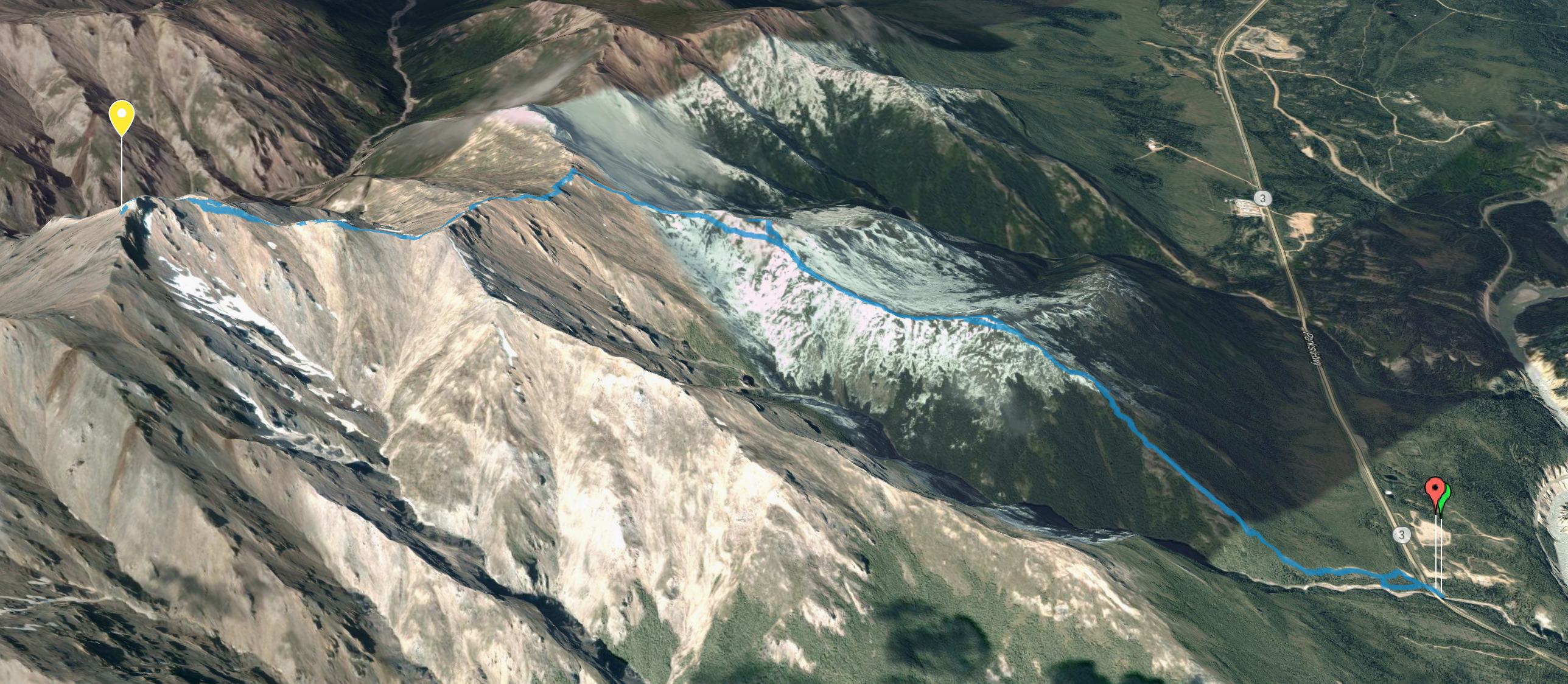
Sunday was a late start, but we did a full on hike at Bison
Gulch (a ‘gulch’ is
the name for a valley formed by erosion). I recorded the hike on
Strava and plotted it on Google
Maps:
Photos from the hike start
here
in the album. It was pretty brutal, we climbed 1,259 m and a lot of that
towards the end was over very loose shale. Here’s one of us up near the top:
It’s lucky we went when we did; a couple of weeks later and it would have been
rather chilly! I think the snow there is from some early falls a week before we
arrived. We were ridiculously fortunate with the weather. It was relatively
warm, with clear skies. The whole place seemed so remote, the air was super
fresh and the stars were all out. Other than the bear, we also saw a couple of
moose and a pair of mountain goats.
All the photos from the trip are in an album on Google
Photos (some of the links above
should jump to certain spots in the album).
This weekend I visited Philadelphia, Pennsylvania’s largest city. It has plenty
of historic sites from the American Revolution, as well as a fairly famous
prison and the Philadelphia Museum of Art which is potentially better known for
“Rocky” than the art.
I didn’t have big plans (I was looking for a relatively quiet weekend after the
week tripping around CO/UT), but still had a busy Saturday. The day started
with a train to the Wissahickon Valley
Park.
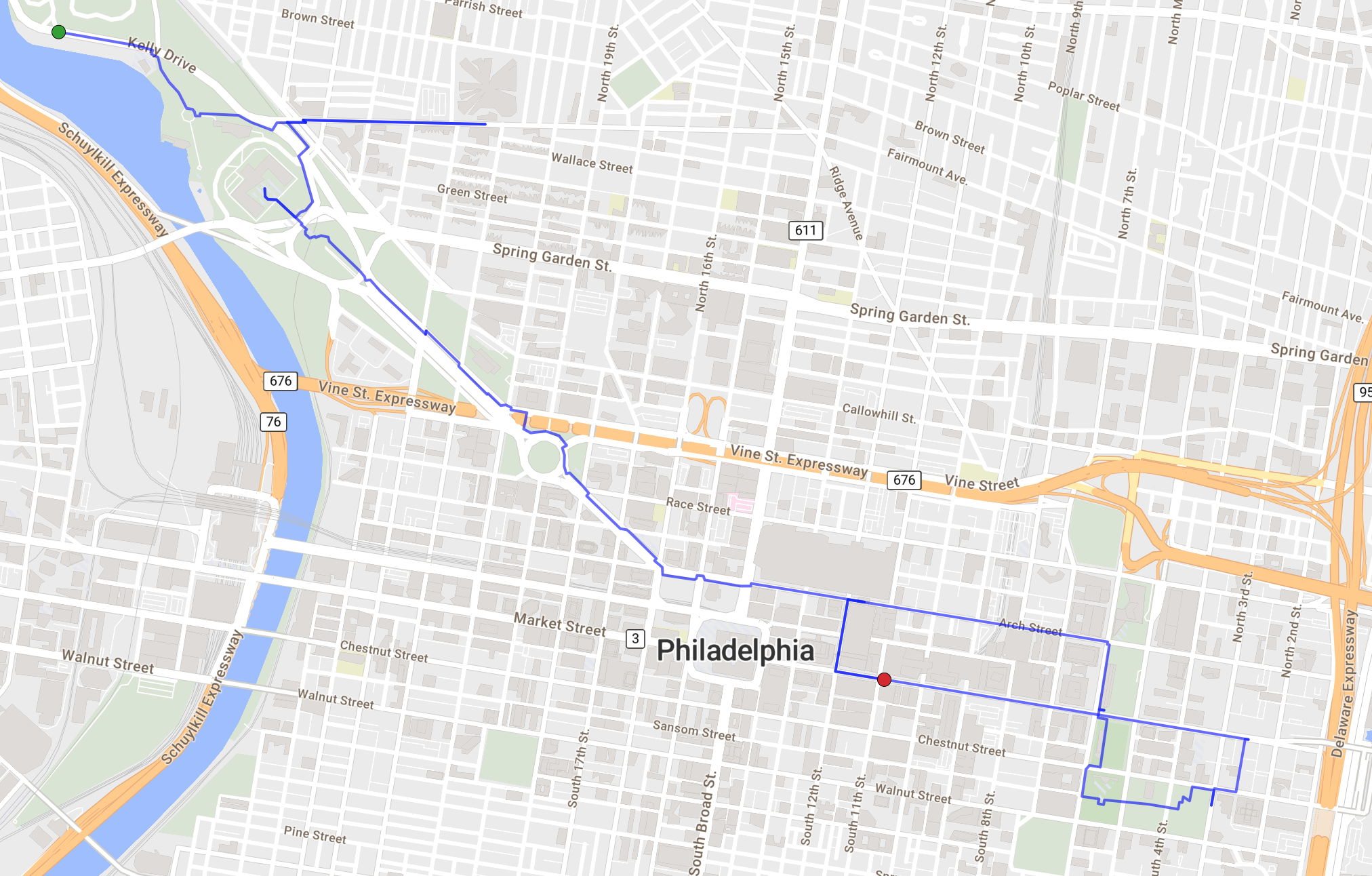
From there I did some hiking/walking through Wissahickon Valley and on to
Boathouse Row, along the Schuylkill
River. That leg (recorded on
Strava) came to 18.5 km, and the
walk downtown came to roughly another 12 km, so I definitely got my steps in
for the day! Here’s the route I took through the city centre:
The walk from Wissahickon Valley also included lots of historic buildings and
bridges. A few highlights of the day follow.
Statue of Tedyuscung
At a point along the trail in Wissahickon Valley, there is a statue positioned
fairly high up the valley, showing a Native American looking out over the
valley. It’s a fairly huge statue, and I didn’t expect to come across it, but
I’ve done some reading about it since. The history of the sculpture is here
(the marble version I saw was dedicated in 1902), though apparently it’s a bit
contentions with one local calling it “a monument to
ignorance”.
Eastern State Penitentiary
Eastern State Penitentiary was the first major prison based on the principle of
keeping prisoners in solitary confinement. The idea was the inmates would
practice penance through silent reflection upon their crimes and behaviour. The
whole prison is designed around this idea. Inmates never saw anyone for the
entire duration of their sentence. The walls are solid and at least a foot
thick. Each prisoner has their own exercise yard. The guards even wore socks
over their shoes so the silence wasn’t disturbed. This understandably went
fairly terribly, with lots of inmates mental health taking a hit. The prison
operated using solitary confinement from 1829 until 1913, and it closed in
1971.
The city council intended to redevelop it, but the site was abandoned for
around a decade and fell to ruin. It was ‘stabilised’ before opening to the
public as a museum in 1994, but large parts of the prison are as they were
after the period of abandonment:
There was also an exhibit at the end of the tour about prisons today and mass
incarceration, which was pretty sobering.
More photos from the day are in an album on Google
Photos.
This year I took a couple of days off work before the conference, and planned a
road trip to do some hiking in the area. I made it to one of the parks near
Boulder, five national parks in the area, and a quick hike near Colorado
Springs on the way back to Denver.
It was a fun week of hiking (89 km) and driving (2,261 km), with a little planning required:
AllTrails worked really well for organising
hikes. I paid for a lifetime Pro membership, which meant I could download
trails for offline use (very handy in the more remote parks)
Airbnb rooms near the hiking spots meant I could get up early and beat the
crowds & heat
The hike had amazing views of the
Flatirons & Royal Arch:
Rocky Mountain National Park
I visited the Rocky Mountains National
Park last year, but as you can see from
the earlier post linked above, the weather was a little different this time.
I was lucky enough to drive past a fairly huge elk chilling very close to the
road.
There was a very friendly marmot up near Sky Pond, though he was probably just
looking for food:
Arches National Park
Sunday saw me driving from Boulder to Arches National
Park in Utah, through Grand Valley.
The Devils
Garden
trail was amazing, with the 88 meter Landscape Arch a highlight.
Canyonlands National Park
Next up was Canyonlands National Park. I
stayed near La Sal on Sunday night, which made the Needles section of the park
a better option than heading back north to Island in the Sky.
The Chesler Park
Loop was one of
the highlights of the whole trip. The landscape looks other-wordly at times,
and it was a lightly trafficked trail.
Mesa Verde National Park
After staying in Cortez on Monday night, I visited Mesa Verde National
Park, a UNESCO World Heritage Site. The
park is best known for the cliff dwellings built by the Ancestral
Puebloans.
I managed to get in early and score a ticket to a guided tour of Cliff
Palace, a dwelling built around
year 1200.
Other than the Cliff Palace tour, the only hike I did here was Petroglyph
Point,
which passes a large petroglyph
panel. The carvings were likely made around the same time as the cliff
dwellings were built.
Great Sand Dunes National Park
The final national park I visited was Great Sand
Dunes. This was a rushed visit, but I
wanted to make a stop in the park to see the contrast of sand dunes and
mountains. In my mind dunes belong in deserts or at the coast, not at 8,200
feet elevation in the foothills of mountains.
Last weekend a I took a couple of days off to see some of the western United
States, with a visit to Zion National
Park and Las
Vegas.
Zion National Park is absolutely stunning. We did a couple of hikes, the first
was to the peak of Angels Landing, a 454 m high rock formation (total elevation
1,760 m). The trail was built in 1926 and is cut into solid rock most of the
way. It’s only 3.9 km to the top, but it felt much longer given the elevation
and the temperature (it was about 40 °C).
The photo below was taken from somewhere near the start of the trail, Angels
Landing is the peak in the foreground of the photo on the left side.
The view from the top was worth it though!
Given how hot it was on the first day, we set out a little earlier for our
second hike to Observation
Point. The
line for the buses into the Canyon was already quite long, so we took the
opportunity to walk the Pa’rus Trail to the second bus stop.
I’m glad the buses were full, as the Pa’rus Trail provided some amazing views
along a fairly flat and safe path. It was nice to have a casual stroll and look
around without needing to worry about veering off the track!
The walk up to Observation Point runs through Echo Canyon Passage, which was a
nice change of landscape and the canyon walls also offered some protection from
the sun.
Observation Point itself made the hike worthwhile, it’s a great vantage point
for almost all of Zion Canyon.
We were all flying out of Las Vegas, so on Sunday afternoon we drove back to
Las Vegas and explored there a bit. It was roughly what I expected - lots of
bright lights and tacky touristy things 🤣. The Fountains of Bellagio were
pretty impressive though!
Sometime in the next couple of days I’m going to publish a bunch of back dated
posts about travel I’ve done recently (or in some cases not so recently). A lot
of these posts are taken straight from emails I sent to family and friends at
the time I did the actual travel, I decided to post them here as email is
where keystrokes go to
die.
This is a bit of a departure from what has been the norm on this blog so far,
and for those following via RSS I’ve introduced categories and separate feeds
for the Software/Tech
category and the Travel
category in addition to the existing feed containing all posts. If you’d rather not hear about travel posts, please update
your subscription :)
Technically, the only interesting part of this is handling the images I wanted
to include in the posts. I’ve included a few images in the past, but never in a
large quantity.
I use Google Photos/Drive for all my photos, and originally tried
hotlinking the photos from there. If this was supported it would have been the
best solution, as I wouldn’t have to duplicate the photos and it would be easy
to include them (though some of them are quite large). Unfortunately (though
unsurprisingly) Google Photos/Drive doesn’t support hotlinking, and any direct
links to images expire after a while.
The next option was using the Google Drive ‘embed’ functionality, which
involves inserting some HTML into the post which will load an IFrame. This
worked, but:
it looked a little clunky on desktop and didn’t scale well on mobile
a Google IFrame means Google tracking cookies
performance was poor - loading all the images on one of the travel posts
using this method resulted in a whole load of extra requests:
I ended up committing them into the Git repository that backs this static site,
but that does mean the repo size is going to grow a lot more than it should. As
it’s just me working on this repo though, I can always use git
filter-branch as a last resort if
I do want to move the images elsewhere. To avoid bloating the repo too much and
to keep loading times low I did fairly aggressively reduce the file size with
ImageMagick:
The final change was adding lazy loading using Lozad.js. Thankfully I
include almost all the images on my site using a custom Jekyll
include so I just had to include the library and change one
file to get lazy loading across the board.